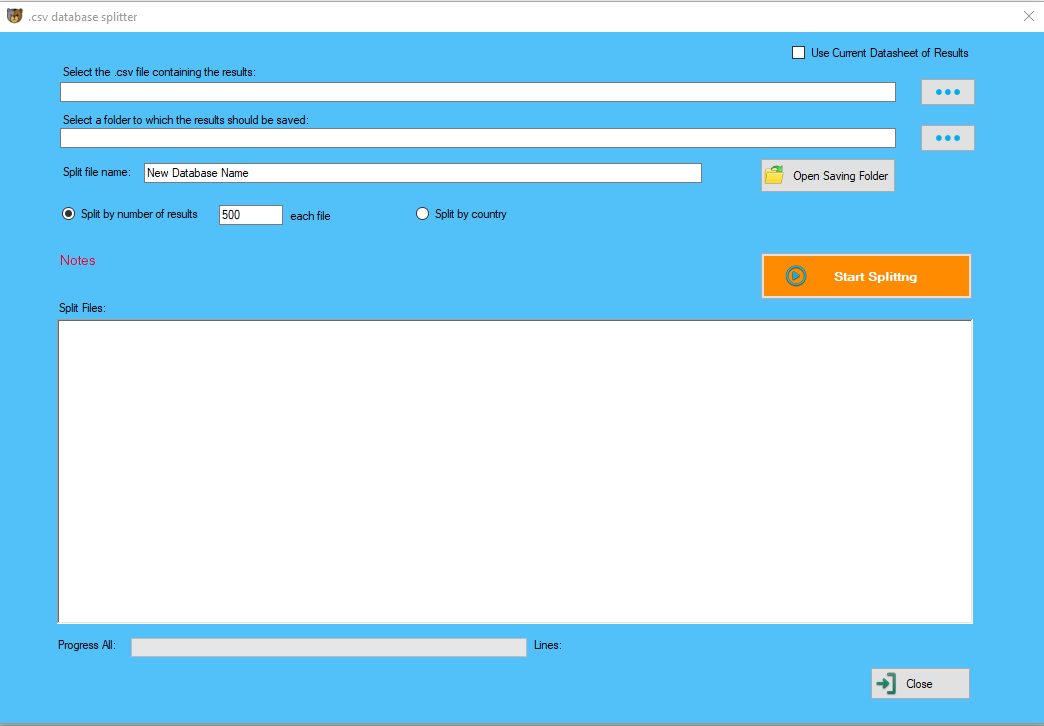
Data Scraping
Data Scraping
The two most typical use instances are price scraping and content theft. Resources wanted to runweb scraper botsare substantial—so much in order that reliable scraping bot operators heavily spend money on servers to process the huge quantity of information being extracted. Web scraping is the method of using bots to extract content material and information from a web site. Since 2006 we have seen most every type of scraping requirement you can imagine. In that time we have served numerous shoppers throughout nearly every main industry.
Contents
An various to rvest for desk scraping is to make use of the XML package. The XML package deal supplies a handy readHTMLTable() function to extract data from HTML tables in HTML documents. By passing the URL to readHTMLTable(), the data in every table is read and saved as an information frame. In a scenario like our working example the place multiple tables exists, the data frames shall be saved in a listing much like rvest’s html_table. 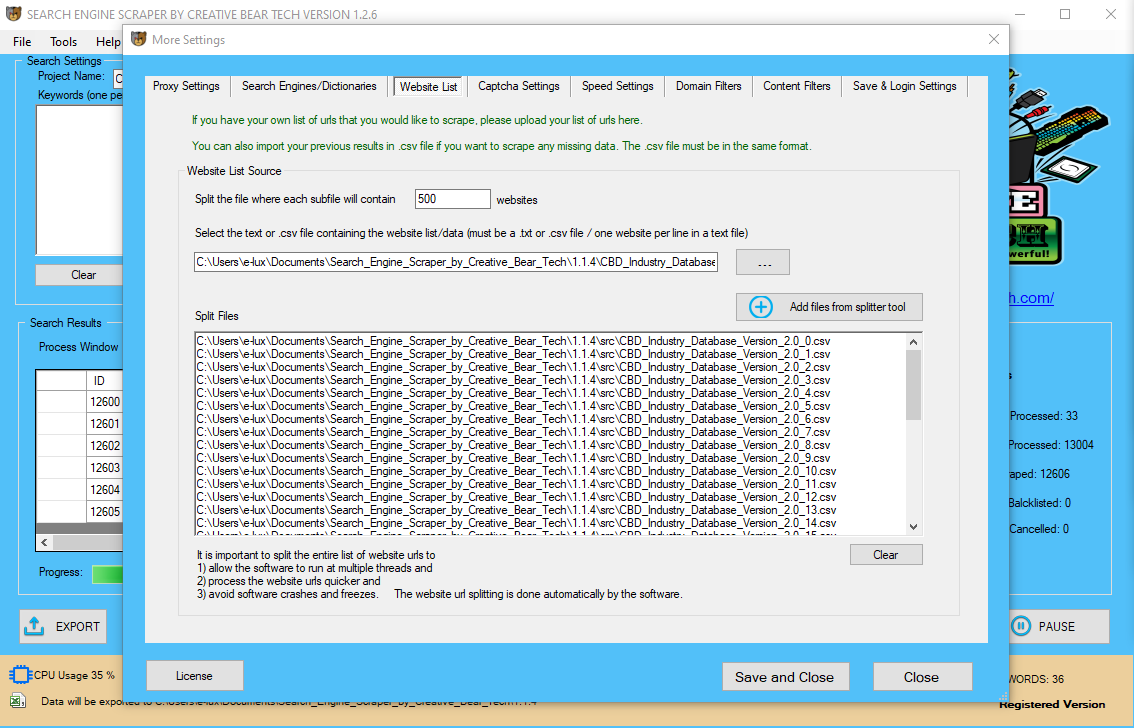
Screen Scraping
An instance can be to seek out and replica names and telephone numbers, or companies and their URLs, to an inventory (contact scraping). Web pages are built utilizing text-based mark-up languages (HTML and XHTML), and frequently comprise a wealth of helpful information in text kind.
Web Scraping
Remember if you intend to scrape / crawl web pages every further second lost for simulating user interaction means nearly an extra three hours of computing time. Resorting to simulating user interplay is often an overkill utilized by newbie Web Scrapers who are often to lazy to investigate the underlying Javascript and internet server calls.
Personal Tools
While web scraping can be carried out manually by a software program consumer, the term typically refers to automated processes applied utilizing a bot or web crawler. It is a form of copying, in which specific information is gathered and copied from the online, usually right into a central local database or spreadsheet, for later retrieval or evaluation. Data Scraper slots straight into your Chrome browser extensions, permitting you to choose from a range of prepared-made data scraping “recipes” to extract information from whichever web web page is loaded in your browser. Report mining is the extraction of information from human-readable pc stories.
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
You’ll have to specify the precise knowledge variables you want the API to retrieve so you’ll need to be familiar with, or have access to, the information library. Remember that html_nodes() does not parse the information; rather, it acts as a CSS selector. To parse the HTML table knowledge we use html_table(), which would create an inventory containing 15 knowledge frames. However, not often do we have to scrape each HTML table from a page, particularly since some HTML tables don’t catch any information we're likely interested in (i.e. desk of contents, desk of figures, footers). A strong answer will usually require issues now not out there, such as source code, system documentation, APIs, or programmers with experience in a 50-year-old pc system. In such instances, the only possible resolution could also be to write a display screen scraper that "pretends" to be a consumer at a terminal. The content material of a page may be parsed, searched, reformatted, its knowledge copied into a spreadsheet, and so forth. Web scrapers sometimes take one thing out of a web page, to utilize it for another function somewhere else. Conventional data extraction requires a connection to a working source system, suitable connectivity standards or an API, and often complex querying. By utilizing the supply system's normal reporting choices, and directing the output to a spool file as a substitute of to a printer, static reports may be generated suitable for offline evaluation via report mining. This method can keep away from intensive CPU utilization during business hours, can minimise end-user licence prices for ERP prospects, and might supply very fast prototyping and development of customized reports. Whereas information scraping and net scraping involve interacting with dynamic output, report mining includes extracting data from information in a human-readable format, corresponding to HTML, PDF, or text. These may be simply generated from nearly any system by intercepting the info feed to a printer. However, most net pages are designed for human end-customers and never for ease of automated use. Companies like Amazon AWS and Google provide internet scraping tools, services, and public knowledge out there freed from price to finish-users.
Pet Stores Email Address List & Direct Mailing Databasehttps://t.co/mBOUFkDTbE
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Pet Care Industry Email List is ideal for all forms of B2B marketing, including telesales, email and newsletters, social media campaigns and direct mail. pic.twitter.com/hIrQCQEX0b
For those of you I have gathered an inventory of primary out-of-the-box solutions that may enable you to quickly extract some web DuckDuckGo Search Engine Scraper content material. Excel is an efficient tool for newbie Web Scrapers due to this fact I will typically resort to code examples in VBA. The first three present some metadata data (status, response time, and message if applicable). The information we are concerned about is in the 4th (Results$sequence$information) list item which contains 31 observations. There are many software tools out there that can be utilized to customize internet-scraping solutions. Some net scraping software program may also be used to extract data from an API immediately. Web scraping an internet page involves fetching it and extracting from it. Fetching is the downloading of a web page (which a browser does if you view the page). Therefore, web crawling is a primary part of internet scraping, to fetch pages for later processing. The .zip archive file format is meant to compress files and are typically used on information of significant dimension. For occasion, the Consumer Expenditure Survey knowledge we downloaded in the previous example is over 10MB. Obviously there may be instances in which we want to get specific knowledge in the .zip file to analyze however not all the time completely retailer the complete .zip file contents. In these situations we will use the next process proposed by Dirk Eddelbuettel to temporarily obtain the .zip file, extract the specified data, after which discard the .zip file. Although when presenting more refined methods I will certainly reach out for some Python and C#. For example, on-line local business directories invest significant amounts of time, cash and energy constructing their database content.
- Some internet scraping software program may also be used to extract data from an API immediately.
- There are many software program tools obtainable that can be utilized to customise web-scraping options.
- Therefore, web crawling is a primary component of web scraping, to fetch pages for later processing.
- Web scraping an internet page involves fetching it and extracting from it.
As you’ve seen earlier than, .textual content solely accommodates the seen text content material of an HTML factor. To get the actual URL, you want to extract a kind of attributes instead of discarding it. You’ve efficiently scraped some HTML from the Internet, but whenever you take a look at it now, it simply looks like an enormous mess. There are tons of HTML elements right here and there, 1000's of attributes scattered around—and wasn’t there some JavaScript mixed in as well? It’s time to parse this prolonged code response with Beautiful Soup to make it more accessible and pick out the data that you’re interested in. Excel PowerQuery – From Web featureExcel Power Query is a powerful must-have Microsoft Add-In to Excel which you can find here. Just click the button, enter your required URL and select the desk you need to scrape from the URL. I assume not all of you might be reviewing this Web Scraping Tutorial to master the art of Web Scraping. For some it's sufficient to be able to extract some simple internet content material without having to know what XPath or Javascript is.
Jewelry Stores Email List and Jewelry Contacts Directoryhttps://t.co/uOs2Hu2vWd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Jewelry Stores Email List consists of contact details for virtually every jewellery store across all states in USA, UK, Europe, Australia, Middle East and Asia. pic.twitter.com/whSmsR6yaX
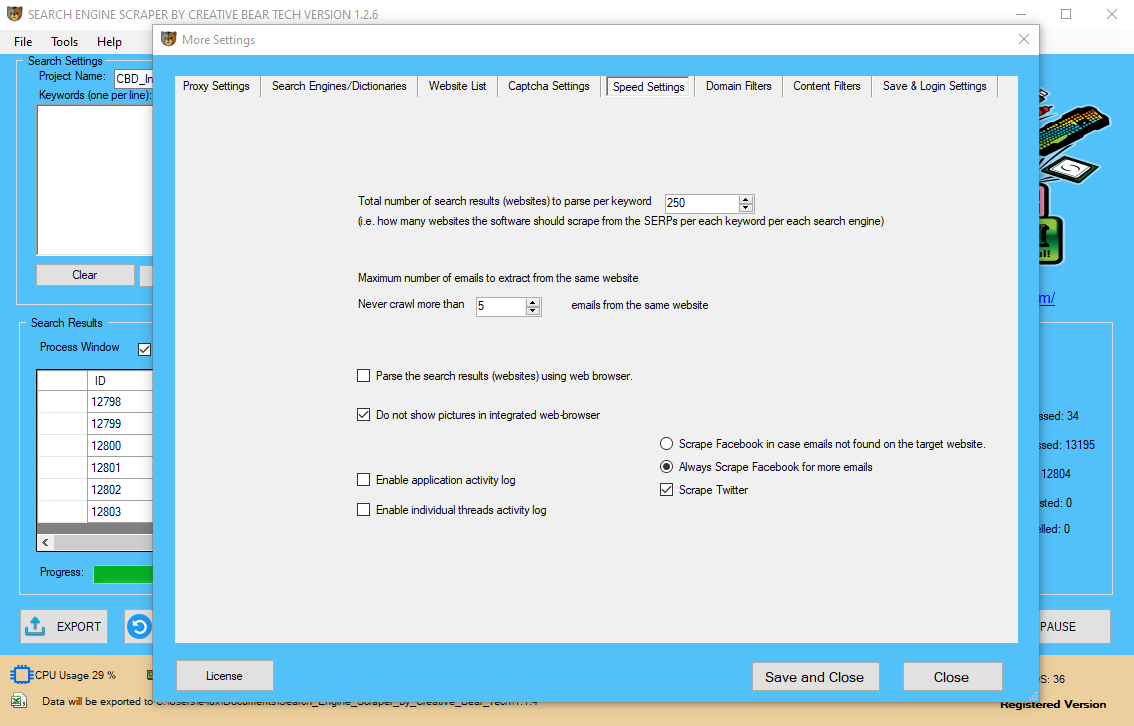
Automated web scraping is usually a resolution to speed up the info assortment course of. You write your code as soon as and it'll get the data you need many instances and from many pages. I will do telephone Scrape Emails with Email Address book knowledge scraping and supply you high quality data. If web site block or Captcha then proxies might be used for scrape data. A subtle and resilient implementation of this kind, built on a platform providing the governance and management required by a significant enterprise—e.g. I am having 4+years real time market experience in Python Development, Web Scraping and Java Android. The methods above principally cowl Yellow Pages Business Directory Scraper most popular Web Scraping techniques. Knowing all of them principally guarantees that it is possible for you to to scrape and crawl any website, whether or not static or dynamic, whether or not utilizing POST or GET or requiring person interaction. The rtimes bundle offers an interface to Congress, Campaign Finance, Article Search, and Geographic APIs provided by the New York Times. The knowledge libraries and documentation for the several APIs obtainable could be discovered here. I simply call the series identifier within the blsAPI() function which pulls the JSON knowledge object. We can then use the fromJSON() function from the rjson package deal to convert to an R knowledge object (a listing on this case). At the outset I talked about how OAuth is an authorization framework that gives credentials as proof for access. Many APIs are open to the general public and solely require an API key; nonetheless, some APIs require authorization to account data (think personal Facebook & Twitter accounts). To access these accounts we must provide correct credentials and OAuth authentication allows us to do this. For our information scraping objective, we wrote a Python script to make and obtain REST API calls. The data for this project was to be obtained by using the REST API supplied by Twitch. They provide clear directions on how to construction GET requests they usually return the data in JSON format.
JustCBD Responds to COVID19 by Donating Face Masks to Homeless - Miami Rescue Mission, Floridahttps://t.co/83eoOIpLFKhttps://t.co/XgTq2H2ag3 @JustCbd @PeachesScreams pic.twitter.com/Y7775Azisx
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
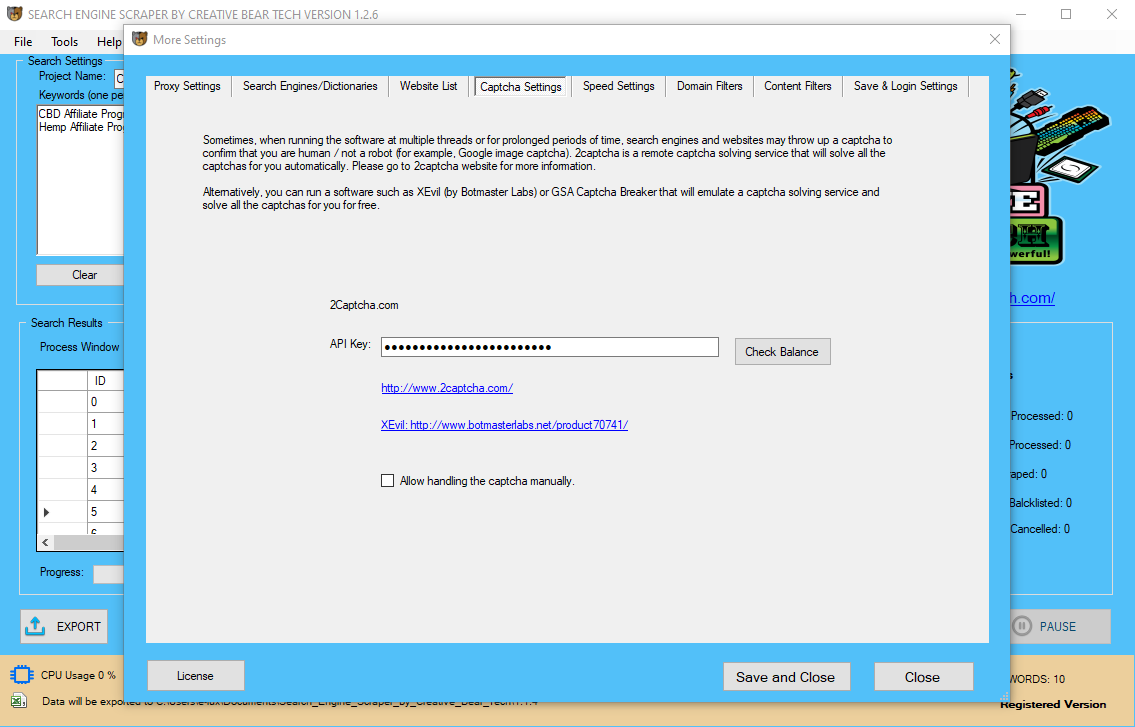 In such case you should present me proxy API key as properly for data scraping. Excel is a great device for beginner coders, as a result of its ubiquity and, because it contains both a developing and testing environment. Therefore I want to introduce a easy Web Scraping Add-In that principally allows you to extract text and knowledge off nearly any static web site. Since the project required evaluation of “LIVE” twitch data, we wrote a Python script to do this. Although Twitch provides this knowledge via simply accessible APIs, we would have liked to have a headless machine to just run our script each 10 minutes. Web scraping, internet harvesting, or internet information extraction is information scraping used for extracting information from web sites. Web scraping software program could entry the World Wide Web directly using the Hypertext Transfer Protocol, or via an online browser. This section just isn't meant to explain the details of OAuth (for that see this, this, and this) however, somewhat, the way to use httr in instances when OAuth is required. Although quite a few R API packages can be found, and cover a wide range of knowledge, you may finally run into a scenario the place you want to leverage a company’s API however an R bundle doesn't exist. httr was developed by Hadley Wickham to easily work with net APIs. It provides a number of features (i.e. HEAD(), POST(), PATCH(), PUT() and DELETE()); nonetheless, the perform we're most involved with today is Get(). We use the Get() function to entry an API, present it some request parameters, and obtain an output. Thankfully, the world offers other methods to use that surfer’s mindset! Instead of trying on the job site every day, you should use Python to assist automate the repetitive parts of your job search. You can use this kind of automation in numerous eventualities, corresponding to extracting lists of products and their costs from e-commerce web sites. Hence I summarize the tools I use in this brief Web Scraping Tutorial. Unlike display screen scraping, which only copies pixels displayed onscreen, web scraping extracts underlying HTML code and, with it, knowledge saved in a database. While you were inspecting the web page, you found that the hyperlink is a part of the factor that has the title HTML class. The present code strips away the whole hyperlink when accessing the .textual content attribute of its parent component. As I mentioned above usually Web Scrapers accept the easy strategy – simulating user interaction. That is strictly why I first introduced the XMLHttpRequest object which makes HTTP calls instead of IE in VBA or Selenium. Beginner Web Scrapers will always favor copying user interaction, generally even being to lazy to inject it via Javascript and doing it on a topmost seen internet browser window. The strategy beneath explains how you need to leverage all the tools talked about above so as to optimize your Web Scraping solution. In contrast, if you attempt to get the information you want manually, you may spend lots of time clicking, scrolling, and looking. This is especially true when you want massive amounts of knowledge from websites which are frequently updated with new content material. Click Yes and select the following 20 button below the search ends in Wikipedia. The project is updated and a Data Scraping sequence is displayed in the Designer panel. A DataTable variable, ExtractDataTable has been routinely generated. The information we offer has been used for purposes as small as mailing lists and up to populating worth tracking systems for a number of Fortune 500 corporations. Our clients are very loyal as a result of they've confidence in our abilities and know that we are able to handle any job. Finally, you write one convenient perform that takes as enter the URL of the touchdown page of an organization and the label you wish to give the corporate. The map operate applies the get_data_from_url() operate in sequence, but it does not should. One might apply parallelisation here, such that a number of CPUs can each get the reviews for a subset of the pages and they're solely combined at the end. Newer types of web scraping contain listening to knowledge feeds from internet servers. For example, JSON is commonly used as a transport storage mechanism between the consumer and the webserver. I can pull all of the tweets that present up on my private timeline utilizing the GET() perform and the entry cridentials I saved in twitter_token. I then use content material() to transform to an inventory and I can start to analyze the data. Collecting information from the web is not a simple course of as there are lots of technologies used to distribute net content material (i.e. HTML, XML, JSON). Therefore, dealing with extra superior web scraping requires familiarity in accessing knowledge stored in these technologies via R. Through this part I will provide an introduction to a number of the elementary tools required to carry out basic web scraping. This contains importing spreadsheet information recordsdata saved online, scraping HTML textual content, scraping HTML table data, and leveraging APIs to scrape knowledge. To better perceive how one can take advantage of the information scraping functionality, let's create an automation project that extracts some specific info from Wikipedia and writes it to an Excel spreadsheet. This approach can provide a fast and easy path to acquiring information while not having to program an API to the source system. As a concrete example of a traditional display screen scraper, contemplate a hypothetical legacy system relationship from the Nineteen Sixties—the daybreak of computerized knowledge processing. Computer to user interfaces from that era were typically simply textual content-based dumb terminals which weren't much more than digital teleprinters (such systems are nonetheless in use today[update], for varied reasons). The want to interface such a system to more fashionable systems is common. Scraping can result in all of it being launched into the wild, utilized in spamming campaigns or resold to opponents. Any of those occasions are likely to impression a enterprise’ backside line and its day by day operations. In price scraping, a perpetrator sometimes makes use of a botnet from which to launch scraper bots to inspect competing enterprise databases. The aim is to access pricing information, undercut rivals and increase sales. Web scraping is considered malicious when data is extracted with out the permission of website house owners. Now as we know tips on how to extract textual content and HTML components from HTML all we need to do is to have the ability to obtain the HTML knowledge from the Website. These strategies permit you to obtain HTML content from static websites or URLs with specified GET parameters. Now earlier than we jump into more sophisticated scraping methods I want to introduce you to the fundamentals of string manipulation and text extraction. Websites are mostly HTML textual content files subsequently being able to manipulate and extract textual content from them is a must have capability. Generally, you possibly can examine the visual components of a website utilizing net development instruments native to your browser. The thought behind this is that all the content of a web site, even if dynamically created, is tagged indirectly within the supply code. These tags are usually sufficient to pinpoint the information you are trying to extract.
In such case you should present me proxy API key as properly for data scraping. Excel is a great device for beginner coders, as a result of its ubiquity and, because it contains both a developing and testing environment. Therefore I want to introduce a easy Web Scraping Add-In that principally allows you to extract text and knowledge off nearly any static web site. Since the project required evaluation of “LIVE” twitch data, we wrote a Python script to do this. Although Twitch provides this knowledge via simply accessible APIs, we would have liked to have a headless machine to just run our script each 10 minutes. Web scraping, internet harvesting, or internet information extraction is information scraping used for extracting information from web sites. Web scraping software program could entry the World Wide Web directly using the Hypertext Transfer Protocol, or via an online browser. This section just isn't meant to explain the details of OAuth (for that see this, this, and this) however, somewhat, the way to use httr in instances when OAuth is required. Although quite a few R API packages can be found, and cover a wide range of knowledge, you may finally run into a scenario the place you want to leverage a company’s API however an R bundle doesn't exist. httr was developed by Hadley Wickham to easily work with net APIs. It provides a number of features (i.e. HEAD(), POST(), PATCH(), PUT() and DELETE()); nonetheless, the perform we're most involved with today is Get(). We use the Get() function to entry an API, present it some request parameters, and obtain an output. Thankfully, the world offers other methods to use that surfer’s mindset! Instead of trying on the job site every day, you should use Python to assist automate the repetitive parts of your job search. You can use this kind of automation in numerous eventualities, corresponding to extracting lists of products and their costs from e-commerce web sites. Hence I summarize the tools I use in this brief Web Scraping Tutorial. Unlike display screen scraping, which only copies pixels displayed onscreen, web scraping extracts underlying HTML code and, with it, knowledge saved in a database. While you were inspecting the web page, you found that the hyperlink is a part of the factor that has the title HTML class. The present code strips away the whole hyperlink when accessing the .textual content attribute of its parent component. As I mentioned above usually Web Scrapers accept the easy strategy – simulating user interaction. That is strictly why I first introduced the XMLHttpRequest object which makes HTTP calls instead of IE in VBA or Selenium. Beginner Web Scrapers will always favor copying user interaction, generally even being to lazy to inject it via Javascript and doing it on a topmost seen internet browser window. The strategy beneath explains how you need to leverage all the tools talked about above so as to optimize your Web Scraping solution. In contrast, if you attempt to get the information you want manually, you may spend lots of time clicking, scrolling, and looking. This is especially true when you want massive amounts of knowledge from websites which are frequently updated with new content material. Click Yes and select the following 20 button below the search ends in Wikipedia. The project is updated and a Data Scraping sequence is displayed in the Designer panel. A DataTable variable, ExtractDataTable has been routinely generated. The information we offer has been used for purposes as small as mailing lists and up to populating worth tracking systems for a number of Fortune 500 corporations. Our clients are very loyal as a result of they've confidence in our abilities and know that we are able to handle any job. Finally, you write one convenient perform that takes as enter the URL of the touchdown page of an organization and the label you wish to give the corporate. The map operate applies the get_data_from_url() operate in sequence, but it does not should. One might apply parallelisation here, such that a number of CPUs can each get the reviews for a subset of the pages and they're solely combined at the end. Newer types of web scraping contain listening to knowledge feeds from internet servers. For example, JSON is commonly used as a transport storage mechanism between the consumer and the webserver. I can pull all of the tweets that present up on my private timeline utilizing the GET() perform and the entry cridentials I saved in twitter_token. I then use content material() to transform to an inventory and I can start to analyze the data. Collecting information from the web is not a simple course of as there are lots of technologies used to distribute net content material (i.e. HTML, XML, JSON). Therefore, dealing with extra superior web scraping requires familiarity in accessing knowledge stored in these technologies via R. Through this part I will provide an introduction to a number of the elementary tools required to carry out basic web scraping. This contains importing spreadsheet information recordsdata saved online, scraping HTML textual content, scraping HTML table data, and leveraging APIs to scrape knowledge. To better perceive how one can take advantage of the information scraping functionality, let's create an automation project that extracts some specific info from Wikipedia and writes it to an Excel spreadsheet. This approach can provide a fast and easy path to acquiring information while not having to program an API to the source system. As a concrete example of a traditional display screen scraper, contemplate a hypothetical legacy system relationship from the Nineteen Sixties—the daybreak of computerized knowledge processing. Computer to user interfaces from that era were typically simply textual content-based dumb terminals which weren't much more than digital teleprinters (such systems are nonetheless in use today[update], for varied reasons). The want to interface such a system to more fashionable systems is common. Scraping can result in all of it being launched into the wild, utilized in spamming campaigns or resold to opponents. Any of those occasions are likely to impression a enterprise’ backside line and its day by day operations. In price scraping, a perpetrator sometimes makes use of a botnet from which to launch scraper bots to inspect competing enterprise databases. The aim is to access pricing information, undercut rivals and increase sales. Web scraping is considered malicious when data is extracted with out the permission of website house owners. Now as we know tips on how to extract textual content and HTML components from HTML all we need to do is to have the ability to obtain the HTML knowledge from the Website. These strategies permit you to obtain HTML content from static websites or URLs with specified GET parameters. Now earlier than we jump into more sophisticated scraping methods I want to introduce you to the fundamentals of string manipulation and text extraction. Websites are mostly HTML textual content files subsequently being able to manipulate and extract textual content from them is a must have capability. Generally, you possibly can examine the visual components of a website utilizing net development instruments native to your browser. The thought behind this is that all the content of a web site, even if dynamically created, is tagged indirectly within the supply code. These tags are usually sufficient to pinpoint the information you are trying to extract.